Remove \(\lambda\)-rules, then unit productions, and
then useless productions from the grammar \(G\) above.
New grammar \(G'\) is:
\(S \rightarrow Aa \mid a\)
\(A \rightarrow AA \mid ABa \mid Aa \mid Ba \mid a\)
\(B \rightarrow BBa \mid Ba \mid a \mid b\)
Is \(ba\) in \(L(G)\)? Running time?
Try all possible derivations, there will be at most \(|w|\) rounds.
NOTE THIS IS NOT LINEAR TIME, IT TAKES A LONG TIME.
Actual time is \(|w|*p\) where \(p\) is the maximum number of
rules for any variable.
Using \(B \rightarrow b\) gives that \(b\) is in
\(\mbox{FIRST}(B)\).
Using \(B \rightarrow \lambda\) gives that \(\lambda\) is
in \(\mbox{FIRST}(B)\).
\(\mbox{FIRST}(S) = \{a, b, \lambda\}\)
Using \(S \rightarrow aSc\) gives that \(a\) is in
\(\mbox{FIRST}(S)\).
Using \(S \rightarrow B\) and \(\lambda\) is in
\(\mbox{FIRST}(B)\) gives that everything in
\(\mbox{FIRST}(B)\) is in \(\mbox{FIRST}(S)\), so \(b\)
and \(\lambda\) are in \(\mbox{FIRST}(S)\).
\(\$\) goes into \(\mbox{FOLLOW}(S)\) by rule 1.
Then \(c\) goes into \(\mbox{FOLLOW}(S)\) by rule 2 since
\(S \rightarrow aSc\) and \(\mbox{FIRST}(c) = \{c\}\).
\(\mbox{FOLLOW}(B) = \{ \$, c \}\)
By rule 3 and \(S \rightarrow B\), \(\mbox{FOLLOW}(S)\) is
added to \(\mbox{FOLLOW}(B)\).
When the grammar is large, the parsing routine will have many cases.
Alternatively, store the information for which rule to apply in
a table.
Rows: variables
Columns: terminals, $ (end of string marker)
LL[i,j] contains the right-hand-side of a rule.
This right-hand-side is pushed onto the stack when the
left-hand-side of the rule is the variable representing the
\(i\) th row and the lookahead is the symbol representing the
\(j\) th column.
For any CFG that we can specify by this type of parse table,
we can use a generic parser to determine if strings
are in this language.
When the grammar has a \(\lambda\)-rule, it
can be difficult to compute parse tables.
In this example,
\(A\) can disappear (due to \(A \rightarrow \lambda\)).
So when \(S\) is on the stack, it can be replaced by \(Ac\)
if either “a” or “c” are the lookahead, or it can be replaced
by \(Bc\) if “b” is the lookahead.
\[\begin{split}\begin{array}{c||c|c|c|c}
& a & b & c & \$ \\ \hline \hline
S & aSc & B & B & B \\ \hline
B & \mbox{error} & b & \lambda & \lambda
\end{array}\end{split}\]
Parse string: \(aacc\)
\[\begin{split}\begin{array}{lcccccccc}
&&&&a \\
&&a&&S &S &B \\
&&S& S& c& c& c& c \\
\mbox{Stack:} & \underline{S} & \underline{c} & \underline{c} & \underline{c}
& \underline{c} & \underline{c} & \underline{c} & \underline{c} \\
\mbox{symbol:} & a & a & a' & a' & c & c& c& c' \\
\end{array}\end{split}\]
where \(a'\) is the second \(a\) in the string and symbol is
the lookahead symbol.
This table is an LL(1) table because only 1 symbol of lookahead is needed.
\[\begin{split}\begin{array}{lccccccccc}
&&&&a \\
&&a&&S &S &B & b\\
&&S& S& c& c& c& c & c \\
\mbox{Stack:} & \underline{S} & \underline{c} & \underline{c} & \underline{c}
& \underline{c} & \underline{c} & \underline{c} & \underline{c}
& \underline{c} \\
\mbox{symbol:} & a & a & a' & a' & b & b& b& c & c' \\
\end{array}\end{split}\]
where \(a'\) is the second \(a\) in the string and symbol
is the lookahead symbol.
This table is an LL(1) table because only 1 symbol of lookahead is needed.


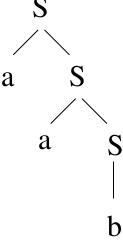
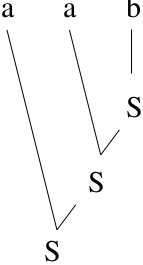
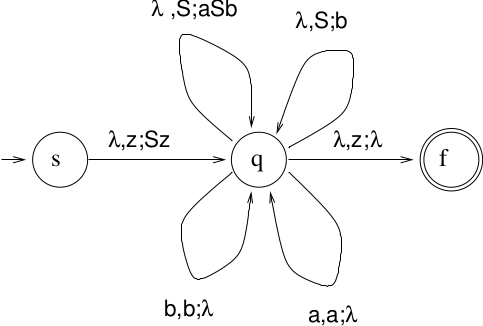 The PDA is nondeterministic.Use lookahead to make it deterministic: determine which rewrite rule to use.
The PDA is nondeterministic.Use lookahead to make it deterministic: determine which rewrite rule to use.