

9.5. Binary Search Trees¶
9.5.1. Binary Search Tree Definition¶
A binary search tree (BST) is a binary tree that conforms to the following condition, known as the binary search tree property. All nodes stored in the left subtree of a node whose key value is \(K\) have key values less than or equal to \(K\). All nodes stored in the right subtree of a node whose key value is \(K\) have key values greater than \(K\). Figure 9.5.1 shows two BSTs for a collection of values. One consequence of the binary search tree property is that if the BST nodes are printed using an inorder traversal, then the resulting enumeration will be in sorted order from lowest to highest.
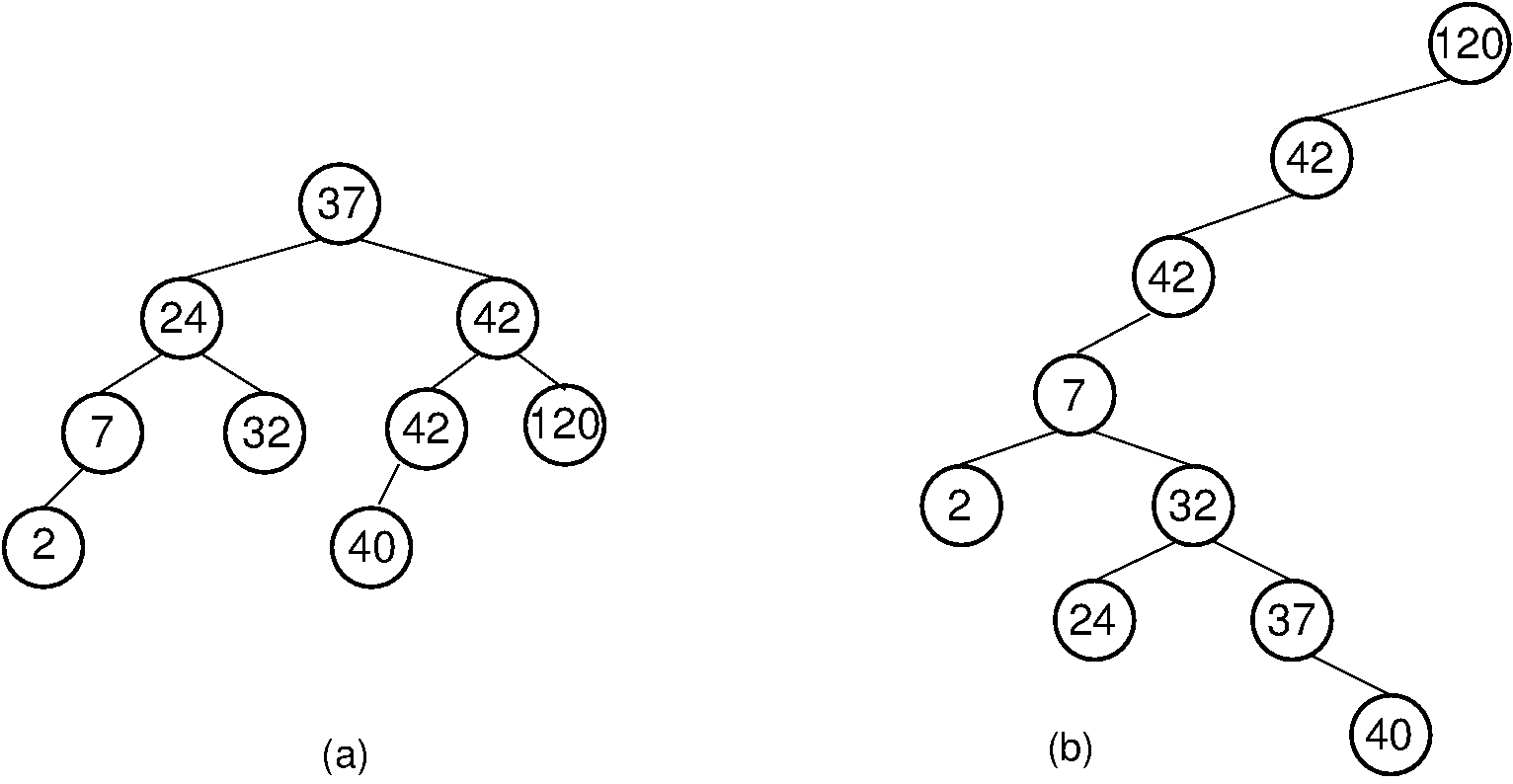
Figure 9.5.1: Two Binary Search Trees for a collection of values. Tree (a) results if values are inserted in the order 37, 24, 42, 7, 2, 40, 42, 32, 120. Tree (b) results if the same values are inserted in the order 120, 42, 42, 7, 2, 32, 37, 24, 40.
Here is a class declaration for the BST.
Recall that there are various ways to deal with
keys and
comparing records
Three typical approaches are key-value pairs,
a special comparison method such as using the Comparator class,
and passing in a comparator function.
Our BST implementation will require that records implement the
Comparable interface.
// Binary Search Tree implementation
class BST {
private BSTNode root; // Root of the BST
private int nodecount; // Number of nodes in the BST
// constructor
BST() { root = null; nodecount = 0; }
// Reinitialize tree
void clear() { root = null; nodecount = 0; }
// Insert a record into the tree.
// Records can be anything, but they must be Comparable
// e: The record to insert.
void insert(Comparable e) {
root = inserthelp(root, e);
nodecount++;
}
// Remove a record from the tree
// k: The key value of record to remove
// Returns the record removed, null if there is none.
Comparable remove(Comparable k) {
Comparable temp = findhelp(root, k); // First find it
if (temp != null) {
root = removehelp(root, k); // Now remove it
nodecount--;
}
return temp;
}
// Return the record with key value k, null if none exists
// k: The key value to find
Comparable find(Comparable k) { return findhelp(root, k); }
// Return the number of records in the dictionary
int size() { return nodecount; }
9.5.1.1. BST Search¶
The first operation that we will look at in detail will find the
record that matches a given key.
Notice that in the BST class, public member function
find calls private member function findhelp.
Method find takes the search key as an explicit parameter
and its BST as an implicit parameter, and returns the record that
matches the key.
However, the find operation is most easily implemented as a
recursive function whose parameters are the root of a
subtree and the search key.
Member findhelp has the desired form for this recursive
subroutine and is implemented as follows.


9.5.2. BST Insert¶
Now we look at how to insert a new node into the BST.
Note that, except for the last node in the path, inserthelp
will not actually change the child pointer for any of the nodes that
are visited.
In that sense, many of the assignments seem redundant.
However, the cost of these additional assignments is worth paying to
keep the insertion process simple.
The alternative is to check if a given assignment is necessary, which
is probably more expensive than the assignment!
We have to decide what to do when the node that we want to insert has a key value equal to the key of some node already in the tree. If during insert we find a node that duplicates the key value to be inserted, then we have two options. If the application does not allow nodes with equal keys, then this insertion should be treated as an error (or ignored). If duplicate keys are allowed, our convention will be to insert the duplicate in the left subtree.
The shape of a BST depends on the order in which elements are inserted. A new element is added to the BST as a new leaf node, potentially increasing the depth of the tree. Figure 9.5.1 illustrates two BSTs for a collection of values. It is possible for the BST containing \(n\) nodes to be a chain of nodes with height \(n\). This would happen if, for example, all elements were inserted in sorted order. In general, it is preferable for a BST to be as shallow as possible. This keeps the average cost of a BST operation low.
9.5.3. BST Remove¶
Removing a node from a BST is a bit trickier than inserting a node, but it is not complicated if all of the possible cases are considered individually. Before tackling the general node removal process, we will first see how to remove from a given subtree the node with the largest key value. This routine will be used later by the general node removal function.
The return value of the deletemax method is the subtree of
the current node with the maximum-valued node in the subtree removed.
Similar to the inserthelp method, each node on the path back to
the root has its right child pointer reassigned to the subtree
resulting from its call to the deletemax method.
A useful companion method is getmax which returns a
pointer to the node containing the maximum value in the subtree.
// Get the maximum valued element in a subtree
private BSTNode getmax(BSTNode rt) {
if (rt.right() == null) return rt;
return getmax(rt.right());
}
Now we are ready for the removehelp method.
Removing a node with given key value \(R\) from the BST
requires that we first find \(R\) and then remove it from the
tree.
So, the first part of the remove operation is a search to find
\(R\).
Once \(R\) is found, there are several possibilities.
If \(R\) has no children, then \(R\)'s parent has its
pointer set to NULL.
If \(R\) has one child, then \(R\)'s parent has
its pointer set to \(R\)'s child (similar to deletemax).
The problem comes if \(R\) has two children.
One simple approach, though expensive, is to set \(R\)'s parent to
point to one of \(R\)'s subtrees, and then reinsert the remaining
subtree's nodes one at a time.
A better alternative is to find a value in one of the
subtrees that can replace the value in \(R\).
Thus, the question becomes: Which value can substitute for the one being removed? It cannot be any arbitrary value, because we must preserve the BST property without making major changes to the structure of the tree. Which value is most like the one being removed? The answer is the least key value greater than the one being removed, or else the greatest key value less than (or equal to) the one being removed. If either of these values replace the one being removed, then the BST property is maintained.
When duplicate node values do not appear in the tree, it makes no difference whether the replacement is the greatest value from the left subtree or the least value from the right subtree. If duplicates are stored in the left subtree, then we must select the replacement from the left subtree. [1] To see why, call the least value in the right subtree \(L\). If multiple nodes in the right subtree have value \(L\), selecting \(L\) as the replacement value for the root of the subtree will result in a tree with equal values to the right of the node now containing \(L\). Selecting the greatest value from the left subtree does not have a similar problem, because it does not violate the Binary Search Tree Property if equal values appear in the left subtree.
| [1] | Alternatively, if we prefer to store duplicate values in the right subtree, then we must replace a deleted node with the least value from its right subtree. |
9.5.4. BST Analysis¶
The cost for findhelp and inserthelp is the depth of
the node found or inserted.
The cost for removehelp is the depth of the node being
removed, or in the case when this node has two children,
the depth of the node with smallest value in its right subtree.
Thus, in the worst case, the cost for any one of these operations is
the depth of the deepest node in the tree.
This is why it is desirable to keep BSTs
balanced, that is, with least possible
height.
If a binary tree is balanced, then the height for a tree of \(n\)
nodes is approximately \(\log n\).
However, if the tree is completely unbalanced, for example in the
shape of a linked list, then the height for a tree with \(n\)
nodes can be as great as \(n\).
Thus, a balanced BST will in the average case have operations costing
\(\Theta(\log n)\), while a badly unbalanced BST can have
operations in the worst case costing \(\Theta(n)\).
Consider the situation where we construct a BST of \(n\) nodes
by inserting records one at a time.
If we are fortunate to have them arrive in an order that results in a
balanced tree (a "random" order is likely to be good
enough for this purpose), then each insertion will cost on average
\(\Theta(\log n)\), for a total cost of
\(\Theta(n \log n)\).
However, if the records are inserted in order of increasing value,
then the resulting tree will be a chain of height \(n\).
The cost of insertion in this case will be
\(\sum_{i=1}^{n} i = \Theta(n^2)\).
Traversing a BST costs \(\Theta(n)\) regardless of the shape of the tree. Each node is visited exactly once, and each child pointer is followed exactly once.
Below is an example traversal, named printhelp.
It performs an inorder traversal on the BST to print the node values
in ascending order.
private void printhelp(BSTNode rt) {
if (rt == null) return;
printhelp(rt.left());
printVisit(rt.value());
printhelp(rt.right());
}
While the BST is simple to implement and efficient when the tree is balanced, the possibility of its being unbalanced is a serious liability. There are techniques for organizing a BST to guarantee good performance. Two examples are the AVL tree and the splay tree. There also exist other types of search trees that are guaranteed to remain balanced, such as the 2-3 Tree.
