

3.2. Analyzing Search in Unsorted Lists¶
3.2.1. Analysis¶
You already know the simplest form of search: the sequential search algorithm. Sequential search on an unsorted list requires \(\Theta(n)\) time in the worst case.
How many comparisons does linear search do on average? A major consideration is whether \(K\) is in list L at all. We can simplify our analysis by ignoring everything about the input except the position of \(K\) if it is found in L. Thus, we have \(n+1\) distinct possible events: That \(K\) is in one of positions 0 to \(n-1\) in L (each position having its own probability), or that it is not in \(L\) at all. We can express the probability that \(K\) is not in L as
where \(\mathbf{P}(x)\) is the probability of event \(x\).
Let \(p_i\) be the probability that \(K\) is in position \(i\) of L (indexed from 0 to \(n-1\). For any position \(i\) in the list, we must look at \(i+1\) records to reach it. So we say that the cost when \(K\) is in position \(i\) is \(i+1\). When \(K\) is not in L, sequential search will require \(n\) comparisons. Let \(p_n\) be the probability that \(K\) is not in L. Then the average cost \(\mathbf{T}(n)\) will be
What happens to the equation if we assume all the \(p_i\) 's are equal (except \(p_n\))?
Depending on the value of \(p_n\), \(\frac{n+1}{2} \leq \mathbf{T}(n) \leq n\).
3.2.2. Lower Bounds Proofs¶
Given an (unsorted) list L of \(n\) elements and a search key \(K\), we seek to identify one element in L which has key value \(k\), if any exists. For the rest of this discussion, we will assume that the key values for the elements in L are unique, that the set of all possible keys is totally ordered (that is, the operations \(<\), \(=\), and \(>\) are defined for all pairs of key values), and that comparison is our only way to find the relative ordering of two keys. Our goal is to solve the problem using the minimum number of comparisons.
Given this definition for searching, we can easily come up with the standard sequential search algorithm, and we can also see that the lower bound for this problem is "obviously" \(n\) comparisons. (Keep in mind that the key \(K\) might not actually appear in the list.) However, lower bounds proofs are a bit slippery, and it is instructive to see how they can go wrong.
Theorem 3.2.1
The lower bound for the problem of searching in an unsorted list is \(n\) comparisons.
Here is our first attempt at proving the theorem.
Proof 1
We will try a proof by contradiction. Assume an algorithm \(A\) exists that requires only \(n-1\) (or less) comparisons of \(K\) with elements of L. Because there are \(n\) elements of L, \(A\) must have avoided comparing \(K\) with L [\(n\)]. We can feed the algorithm an input with \(K\) in position \(n\). Such an input is legal in our model, so the algorithm is incorrect.
Is this proof correct? Hopefully it is reasonably obvious to you that not all algorithms must search through the list in a specific order, so not all algorithms have to look at position L [\(n\)] last.
OK, so we can try to dress up the proof by making the process a bit more flexible.
Proof 2
We will try a proof by contradiction. Assume an algorithm \(A\) exists that requires only \(n-1\) (or less) comparisons of \(K\) with elements of L. Because there are \(n\) elements of L, \(A\) must have avoided comparing \(K\) with L [\(i\)] for some value \(i\). We can feed the algorithm an input with \(K\) in position \(i\). Such an input is legal in our model, so the algorithm is incorrect.
Is this proof correct? Still, no. First of all, any given algorithm need not necessarily consistently skip any given position \(i\) in its \(n-1\) searches. For example, it is not necessary that all algorithms search the list from left to right. It is not even necessary that all algorithms search the same \(n-1\) positions first each time through the list. Perhaps it picks them at random.
Again, we can try to dress up the proof as follows.
Proof 3
On any given run of the algorithm, if \(n-1\) elements are compared against \(K\), then some element position (call it position \(i\)) gets skipped. It is possible that \(K\) is in position \(i\) at that time, and will not be found. Therefore, \(n\) comparisons are required.
Unfortunately, there is another error that needs to be fixed. It is not true that all algorithms for solving the problem must work by comparing elements of L against \(K\). An algorithm might make useful progress by comparing elements of L against each other. For example, if we compare two elements of L, then compare the greater against \(K\) and find that this element is less than \(K\), we know that the other element is also less than \(K\). It seems intuitively obvious that such comparisons won't actually lead to a faster algorithm, but how do we know for sure? We somehow need to generalize the proof to account for this approach.
We will now present a useful abstraction for expressing the state of knowledge for the value relationships among a set of objects. A total order defines relationships within a collection of objects such that for every pair of objects, one is greater than the other. A partially ordered set or poset is a set on which only a partial order is defined. That is, there can be pairs of elements for which we cannot decide which is "greater". For our purpose here, the partial order is the state of our current knowledge about the objects, such that zero or more of the order relations between pairs of elements are known. We can represent this knowledge by drawing directed acyclic graphs (DAGs) showing the known relationships, as illustrated by Figure 3.2.1.
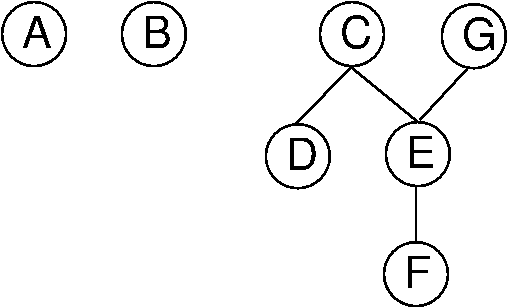
Figure 3.2.1: Illustration of using a poset to model our current knowledge of the relationships among a collection of objects. A directed acyclic graph (DAG) is used to draw the poset (assume all edges are directed downward). In this example, our knowledge is such that we don't know how \(A\) or \(B\) relate to any of the other objects. However, we know that both \(C\) and \(G\) are greater than \(E\) and \(F\). Further, we know that \(C\) is greater than \(D\), and that \(E\) is greater than \(F\)
Proof 4
Initially, we know nothing about the relative order of the elements in L, or their relationship to \(K\). So initially, we can view the \(n\) elements in L as being in \(n\) separate partial orders. Any comparison between two elements in L can affect the structure of the partial orders.
Now, every comparison between elements in L can at best combine two of the partial orders together. Any comparison between \(K\) and an element, say \(A\), in L can at best eliminate the partial order that contains \(A\). Thus, if we spend \(m\) comparisons comparing elements in L we have at least \(n-m\) partial orders. Every such partial order needs at least one comparison against \(K\) to make sure that \(K\) is not somewhere in that partial order. Thus, any algorithm must make at least \(n\) comparisons in the worst case.
