

4.4. Adversarial Lower Bounds Proofs¶
Our next problem will be finding the second largest in a collection of objects. Consider what happens in a standard single-elimination tournament. Even if we assume that the "best" team wins in every game, is the second best the one that loses in the finals? Not necessarily. We might expect that the second best must lose to the best, but they might meet at any time.
Let us go through our standard "algorithm for finding algorithms" by first proposing an algorithm, then a lower bound, and seeing if they match. Unlike our analysis for most problems, this time we are going to count the exact number of comparisons involved and attempt to minimize this count. A simple algorithm for finding the second largest is to first find the maximum (in \(n-1\) comparisons), discard it, and then find the maximum of the remaining elements (in \(n-2\) comparisons) for a total cost of \(2n-3\) comparisons. Is this optimal? That seems doubtful, but let us now proceed to the step of attempting to prove a lower bound.
Theorem 4.4.1
The lower bound for finding the second largest value is \(2n-3\).
Proof
Any element that loses to anything other than the maximum cannot be
second.
So, the only candidates for second place are those that lost to the
maximum.
Function largest might compare the maximum element to
\(n-1\) others.
Thus, we might need \(n-2\) additional comparisons to find the
second largest.
This proof is wrong. It exhibits the necessary fallacy: "Our algorithm does something, therefore all algorithms solving the problem must do the same."
This leaves us with our best lower bounds argument at the moment
being that finding the second largest must cost at least as much as
finding the largest, or \(n-1\).
Let us take another try at finding a better algorithm by adopting a
strategy of divide and conquer.
What if we break the list into halves, and run largest on each
half?
We can then compare the two winners (we have now used a total of
\(n-1\) comparisons), and remove the winner from its half.
Another call to largest on the winner's half yields its second
best.
A final comparison against the winner of the other half gives us the
true second place winner.
The total cost is \(\lceil 3n/2\rceil - 2\).
Is this optimal?
What if we break the list into four pieces?
The best would be \(\lceil 5n/4\rceil\).
What if we break the list into eight pieces?
Then the cost would be about \(\lceil 9n/8\rceil\).
Notice that as we break the list into more parts,
comparisons among the winners of the parts becomes a larger concern.
Looking at this another way, the only candidates for second place are losers to the eventual winner, and our goal is to have as few of these as possible. So we need to keep track of the set of elements that have lost in direct comparison to the (eventual) winner. We also observe that we learn the most from a comparison when both competitors are known to be larger than the same number of other values. So we would like to arrange our comparisons to be against "equally strong" competitors. We can do all of this with a defit{binomial tree}. A binomial tree of height \(m\) has \(2^m\) nodes. Either it is a single node (if \(m=0\)), or else it is two height \(m-1\) binomial trees with one tree's root becoming a child of the other. Figure 4.4.1 illustrates how a binomial tree with eight nodes would be constructed.
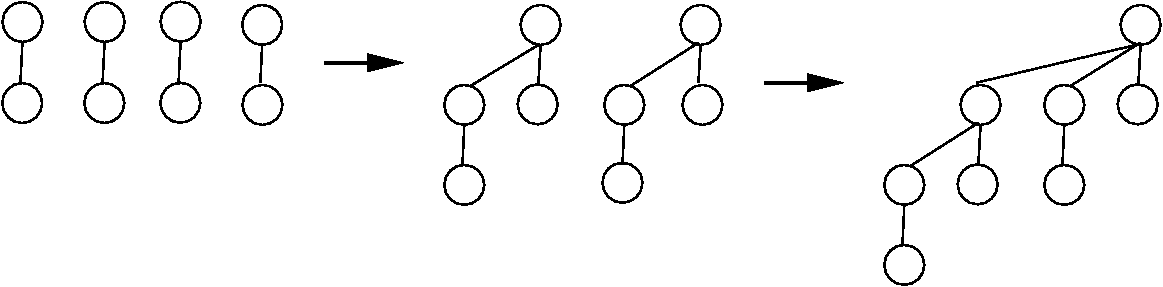
Figure 4.4.1: An example of building a binomial tree. Pairs of elements are combined by choosing one of the parents to be the root of the entire tree. Given two trees of size four, one of the roots is chosen to be the root for the combined tree of eight nodes.
The resulting algorithm is simple in principle: Build the binomial tree for all \(n\) elements, and then compare the \(\lceil \log n\rceil\) children of the root to find second place. We could store the binomial tree as an explicit tree structure, and easily build it in time linear on the number of comparisons as each comparison requires one link be added. Because the shape of a binomial tree is heavily constrained, we can also store the binomial tree implicitly in an array, much as we do for a heap. Assume that two trees, each with \(2^k\) nodes, are in the array. The first tree is in positions 1 to :math`2^k`. The second tree is in positions \(2^k+1\) to \(2^{k+1}\). The root of each subtree is in the final array position for that subtree.
To join two trees, we simply compare the roots of the subtrees. If necessary, swap the subtrees so that tree with the the larger root element becomes the second subtree. This trades space (we only need space for the data values, no node pointers) for time (in the worst case, all of the data swapping might cost \(O(n \log n)\), though this does not affect the number of comparisons required). Note that for some applications, this is an important observation that the array's data swapping requires no comparisons. If a comparison is simply a check between two integers, then of course moving half the values within the array is too expensive. But if a comparison requires that a competition be held between two sports teams, then the cost of a little bit (or even a lot) of book keeping becomes irrelevent.
Because the binomial tree's root has \(\log n\) children, and building the tree requires \(n-1\) comparisons, the number of comparisons required by this algorithm is \(n + \lceil \log n \rceil - 2\). This is clearly better than our previous algorithm. Is it optimal?
We now go back to trying to improve the lower bounds proof. To do this, we introduce the concept of an adversary. The adversary's job is to make an algorithm's cost as high as possible. Imagine that the adversary keeps a list of all possible inputs. We view the algorithm as asking the adversary for information about the algorithm's input. The adversary may never lie, in that its answer must be consistent with the previous answers. But it is permitted to "rearrange" the input as it sees fit in order to drive the total cost for the algorithm as high as possible. In particular, when the algorithm asks a question, the adversary must answer in a way that is consistent with at least one remaining input. The adversary then crosses out all remaining inputs inconsistent with that answer. Keep in mind that there is not really an entity within the computer program that is the adversary, and we don't actually modify the program. The adversary operates merely as an analysis device, to help us reason about the program.
As an example of the adversary concept, consider the standard game of Hangman. Player A picks a word and tells player B how many letters the word has. Player B guesses various letters. If B guesses a letter in the word, then A will indicate which position(s) in the word have the letter. Player B is permitted to make only so many guesses of letters not in the word before losing.
In the Hangman game example, the adversary is imagined to hold a dictionary of words of some selected length. Each time the player guesses a letter, the adversary consults the dictionary and decides if more words will be eliminated by accepting the letter (and indicating which positions it holds) or saying that its not in the word. The adversary can make any decision it chooses, so long as at least one word in the dictionary is consistent with all of the decisions. In this way, the adversary can hope to make the player guess as many letters as possible.
Before explaining how the adversary plays a role in our lower bounds proof, first observe that at least \(n-1\) values must lose at least once. This requires at least \(n-1\) compares. In addition, at least \(k-1\) values must lose to the second largest value. That is, \(k\) direct losers to the winner must be compared. There must be at least \(n + k - 2\) comparisons. The question is: How low can we make \(k\)?
Call the strength of element A[i] the number of
elements that A[i] is (known to be) bigger than.
If A[i] has strength \(a\), and A[j] has
strength \(b\), then the winner has strength \(a + b + 1\).
The algorithm gets to know the (current) strengths for each element,
and it gets to pick which two elements are compared next.
The adversary gets to decide who wins any given comparison.
What strategy by the adversary would cause the algorithm to learn the
least from any given comparison?
It should minimize the rate at which any element improves it strength.
It can do this by making the element with the greater strength win at
every comparison.
This is a "fair" use of an adversary in that it represents the
results of providing a worst-case input for that given algorithm.
To minimize the effects of worst-case behavior, the algorithm's best strategy is to maximize the minimum improvement in strength by balancing the strengths of any two competitors. From the algorithm's point of view, the best outcome is that an element doubles in strength. This happens whenever \(a = b\), where \(a\) and \(b\) are the strengths of the two elements being compared. All strengths begin at zero, so the winner must make at least \(k\) comparisons when \(2^{k-1} < n \leq 2^k\). Thus, there must be at least \(n + \lceil \log n\rceil - 2\) comparisons. So our algorithm is optimal.
