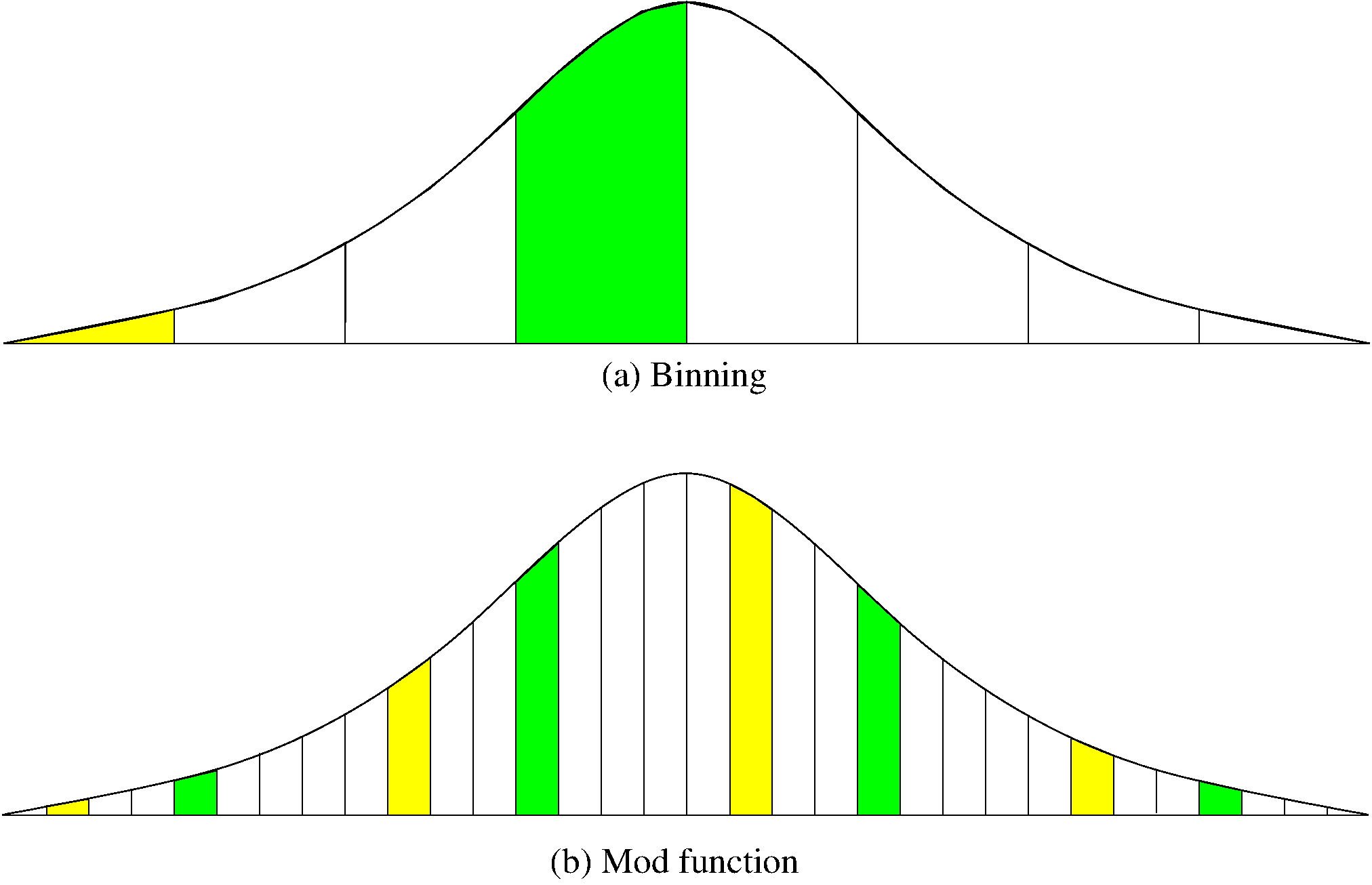
A hash function MUST return a value within the hash table range.
To be practical, a hash function SHOULD evenly distribute the
records stored among the hash table slots.
Ideally, the hash function should distribute records with equal
probability to all hash table slots. In practice, success
depends on distribution of actual records stored.
If we know nothing about the incoming key distribution, evenly
distribute the key range over the hash table slots while avoiding
obvious opportunities for clustering.
If we have knowledge of the incoming distribution, use a
distribution-dependent hash function.
int sascii(String x, int M) {
char ch[];
ch = x.toCharArray();
int xlength = x.length();
int i, sum;
for (sum=0, i=0; i < x.length(); i++)
sum += ch[i];
return sum % M;
}
// Use folding on a string, summed 4 bytes at a timeintsfold(Strings,intM){longsum=0,mul=1;for(inti=0;i<s.length();i++){mul=(i%4==0)?1:mul*256;sum+=s.charAt(i)*mul;}return(int)(Math.abs(sum)%M);}
// Insert e into hash table HT
void hashInsert(const Key& k, const Elem& e) {
int home; // Home position for e
int pos = home = h(k); // Init probe sequence
for (int i=1; EMPTYKEY != (HT[pos]).key(); i++) {
pos = (home + p(k, i)) % M; // probe
if (k == HT[pos].key()) {
println("Duplicates not allowed");
return;
}
}
HT[pos] = e;
}
// Search for the record with Key K
bool hashSearch(const Key& K, Elem& e) const {
int home; // Home position for K
int pos = home = h(K); // Initial position is the home slot
for (int i = 1;
(K != (HT[pos]).key()) && (EMPTYKEY != (HT[pos]).key());
i++)
pos = (home + p(K, i)) % M; // Next on probe sequence
if (K == (HT[pos]).key()) { // Found it
e = HT[pos];
return true;
}
else return false; // K not in hash table
}
Each time p() is called, it generates a value to be added to the
home position to generate the new slot to be examined.
\(p()\) is a function both of the element’s key value, and of
the number of steps taken along the probe sequence.
Not all probe functions use both parameters.