

Deterministic Pushdown Automata¶
1. Deterministic Pushdown Automata¶
Definition: A PDA \(M = (Q, \Sigma, \Gamma, \delta, q_0, z, F)\) is deterministic if for every \(q \in Q\), \(a \in \Sigma \cup \{\lambda\}\), \(b \in \Gamma\):
1. \(\delta(q, a, b)\) contains at most one element2. if \(\delta(q, \lambda, b)\) is not empty, then \(\delta(q, c, b)\) must be empty for every \(c \in \Sigma\).
Definition: \(L\) is a deterministic context-free language (DCFL) if and only if there exists a deterministic PDA \(M\) such that \(L = L(M)\).
Example
The language \(L = \{a^nb^n | n \ge 0\}\) is a deterministic CFL.
accepts the given language. It satisfies the conditions for being deterministic.
Note that this machine DOES have \(\lambda\) transitions. The key point is that there is still only one choice (because of what is sitting on the top of the stack). In that sense, it is not merely a “free ride” transition.
Example
Our previous PDA for \(\{ww^R | w\in{\Sigma}^{+}\}, \Sigma = \{a, b\}\) is nondeterministic.
This violates our conditions for determinism. (Do you see why?)
Now, this fact that we have a PDA that is not deterministic certainly does not prove that \(\{ww^R | w\in{\Sigma}^{+}\}, \Sigma = \{a, b\}\) is not a deterministic CFL.
But, there are CFL’s that are not deterministic. And we will see that this is one of them. This makes intuitive sense. How can we, deterministically, know when to switch from \(w\) to \(w^R\) when scanning from left to right through the input?
Example:
\(L = \{a^nb^n|n \ge 1\} \cup \{a^nb^{2n}| n\ge 1\}\) is a CFL and not a DCFL.
Obviously, both languages are CFL. And obviously, their union is CFL. But imagine how the “obvious” PDA works: The start state transitions to the “correct” machine to recognize a sting in either language. But how can we do this deterministically? We would need a completely different approach.
While that is not a proof that the language is not deterministic, here is one.
Theorem: \(L_1 \cup L_2\) is not a DCFL (because \(a^nb^nc^n\) is not a CFL).
Proof::
Todo
- type: Figure
Show figure
Based on this information, we now can update our model of the Formal Languages Universe.
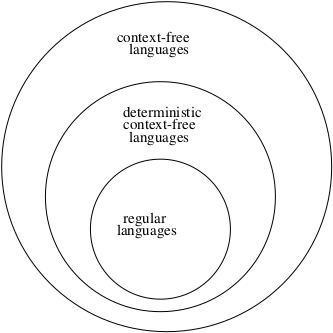
2. Grammars for Deterministic Context-free Languages¶
Now we know that:
All CFL can be generated by a CFG, and implemented by a NPDA.
Not all CFL can be generated using a DPDA.
So some CFG are associated with only non-deterministic PDAs. Nondeterminism gives us something more in terms of capability.
Why do we care? Because we want to parse efficiently. This means, we want to quickly determine if a given string can be generated from a given grammar. Determinism seems to be a fundamental requirement if we hope to do this.
Think of a PDA as a parsing device. No backtracking requires that we can make a decision at every step on what to do next. This is the same as knowing which grammar production comes next. Clearly this is linear time when the grammar has been simplified (no unit productions), because every derivation step consumes an input character. Well… except for \(\lambda\) productions. But we will see soon that these are not really a problem for linear-time processing.
2.1. Top-down Parsing with Lookahead¶
Start with the start symbol Scan left-to-right through the string. At each step, we want only to follow one rule when we look at the current character. Perhaps we don’t see a production for the current character, but instead pop something off the stack (\(\lambda\) production). This is why \(\lambda\) productions are still linear, if we don’t put too much on the stack when we process a character.
2.2. S-grammars¶
Obviously this can be parsed efficiently. But, s-grammars are more restrictive than we want. Lots of useful language constructs cannot be defined using an s-grammar. We want to generalize as much as we can to capture a broader subset of CFLs
2.3. LL(k) Grammars¶
LL means “left-to-right” and “left-most derivation” is constructed. \(k\) means that we can look ahead at most \(k-1\) characters. Every s-grammar is LL, but so are more grammars.
This is not an s-grammar. But, this is an LL grammar. By looking at the next two characters, we always know which rule to apply.
This is a useful grammar! It captures nested parentheses. This is not an LL(k) grammar for any \(k\). (Can you see why not?)
Just because the grammar is not LL(k) does not mean that the language might not be deterministic. The reasoning for why this was not LL(k) should help you to see how to fix the grammar.
