

12.17. Heaps and Priority Queues¶
12.17.1. Heaps and Priority Queues¶
There are many situations, both in real life and in computing applications, where we wish to choose the next "most important" from a collection of people, tasks, or objects. For example, doctors in a hospital emergency room often choose to see next the "most critical" patient rather than the one who arrived first. When scheduling programs for execution in a multitasking operating system, at any given moment there might be several programs (usually called jobs) ready to run. The next job selected is the one with the highest priority. Priority is indicated by a particular value associated with the job (and might change while the job remains in the wait list).
When a collection of objects is organized by importance or priority, we call this a priority queue. A normal queue data structure will not implement a priority queue efficiently because search for the element with highest priority will take \(\Theta(n)\) time. A list, whether sorted or not, will also require \(\Theta(n)\) time for either insertion or removal. A BST that organizes records by priority could be used, with the total of \(n\) inserts and \(n\) remove operations requiring \(\Theta(n \log n)\) time in the average case. However, there is always the possibility that the BST will become unbalanced, leading to bad performance. Instead, we would like to find a data structure that is guaranteed to have good performance for this special application.
This section presents the heap data structure. [1] A heap is defined by two properties. First, it is a complete binary tree, so heaps are nearly always implemented using the array representation for complete binary trees. Second, the values stored in a heap are partially ordered. This means that there is a relationship between the value stored at any node and the values of its children. There are two variants of the heap, depending on the definition of this relationship.
A max heap has the property that every node stores a value that is greater than or equal to the value of either of its children. Because the root has a value greater than or equal to its children, which in turn have values greater than or equal to their children, the root stores the maximum of all values in the tree.
A min heap has the property that every node stores a value that is less than or equal to that of its children. Because the root has a value less than or equal to its children, which in turn have values less than or equal to their children, the root stores the minimum of all values in the tree.
Note that there is no necessary relationship between the value of a node and that of its sibling in either the min heap or the max heap. For example, it is possible that the values for all nodes in the left subtree of the root are greater than the values for every node of the right subtree. We can contrast BSTs and heaps by the strength of their ordering relationships. A BST defines a total order on its nodes in that, given the positions for any two nodes in the tree, the one to the "left" (equivalently, the one appearing earlier in an inorder traversal) has a smaller key value than the one to the "right". In contrast, a heap implements a partial order. Given their positions, we can determine the relative order for the key values of two nodes in the heap only if one is a descendant of the other.
Min heaps and max heaps both have their uses. For example, the Heapsort uses the max heap, while the Replacement Selection algorithm used for external sorting uses a min heap. The examples in the rest of this section will use a max heap.
Be sure not to confuse the logical representation of a heap with its physical implementation by means of the array-based complete binary tree. The two are not synonymous because the logical view of the heap is actually a tree structure, while the typical physical implementation uses an array.
Here is an implementation for max heaps. The class uses records that support the Comparable interface to provide flexibility.
// Max-heap implementation
class MaxHeap {
private Comparable[] Heap; // Pointer to the heap array
private int size; // Maximum size of the heap
private int n; // Number of things now in heap
// Constructor supporting preloading of heap contents
MaxHeap(Comparable[] h, int num, int max)
{ Heap = h; n = num; size = max; buildheap(); }
// Return current size of the heap
int heapsize() { return n; }
// Return true if pos a leaf position, false otherwise
boolean isLeaf(int pos)
{ return (pos >= n/2) && (pos < n); }
// Return position for left child of pos
int leftchild(int pos) {
if (pos >= n/2) return -1;
return 2*pos + 1;
}
// Return position for right child of pos
int rightchild(int pos) {
if (pos >= (n-1)/2) return -1;
return 2*pos + 2;
}
// Return position for parent
int parent(int pos) {
if (pos <= 0) return -1;
return (pos-1)/2;
}
// Insert val into heap
void insert(int key) {
if (n >= size) {
println("Heap is full");
return;
}
int curr = n++;
Heap[curr] = key; // Start at end of heap
// Now sift up until curr's parent's key > curr's key
while ((curr != 0) && (Heap[curr].compareTo(Heap[parent(curr)]) > 0)) {
swap(Heap, curr, parent(curr));
curr = parent(curr);
}
}
// Heapify contents of Heap
void buildheap()
{ for (int i=n/2-1; i>=0; i--) siftdown(i); }
// Put element in its correct place
void siftdown(int pos) {
if ((pos < 0) || (pos >= n)) return; // Illegal position
while (!isLeaf(pos)) {
int j = leftchild(pos);
if ((j<(n-1)) && (Heap[j].compareTo(Heap[j+1]) < 0))
j++; // j is now index of child with greater value
if (Heap[pos].compareTo(Heap[j]) >= 0) return;
swap(Heap, pos, j);
pos = j; // Move down
}
}
// Remove and return maximum value
Comparable removemax() {
if (n == 0) return -1; // Removing from empty heap
swap(Heap, 0, --n); // Swap maximum with last value
if (n != 0) // Not on last element
siftdown(0); // Put new heap root val in correct place
return Heap[n];
}
// Remove and return element at specified position
Comparable remove(int pos) {
if ((pos < 0) || (pos >= n)) return -1; // Illegal heap position
if (pos == (n-1)) n--; // Last element, no work to be done
else {
swap(Heap, pos, --n); // Swap with last value
// If we just swapped in a big value, push it up
while ((pos > 0) && (Heap[pos].compareTo(Heap[parent(pos)]) > 0)) {
swap(Heap, pos, parent(pos));
pos = parent(pos);
}
if (n != 0) siftdown(pos); // If it is little, push down
}
return Heap[n];
}
}
This class definition makes two concessions to the fact that an array-based implementation is used. First, heap nodes are indicated by their logical position within the heap rather than by a pointer to the node. In practice, the logical heap position corresponds to the identically numbered physical position in the array. Second, the constructor takes as input a pointer to the array to be used. This approach provides the greatest flexibility for using the heap because all data values can be loaded into the array directly by the client. The advantage of this comes during the heap construction phase, as explained below. The constructor also takes an integer parameter indicating the initial size of the heap (based on the number of elements initially loaded into the array) and a second integer parameter indicating the maximum size allowed for the heap (the size of the array).
Method heapsize returns the current size of the heap.
H.isLeaf(pos) returns TRUE if position
pos is a leaf in heap H, and FALSE otherwise.
Members leftchild, rightchild,
and parent return the position (actually, the array index)
for the left child, right child, and parent of the position passed,
respectively.
| [1] | Note that the term "heap" is also sometimes used to refer to free store. |
One way to build a heap is to insert the elements one at a time.
Method insert will insert a new element \(V\) into
the heap.


You might expect the heap insertion process to be similar to the
insert function for a BST, starting at the root and working down
through the heap.
However, this approach is not likely to work because the heap must
maintain the shape of a complete binary tree.
Equivalently, if the heap takes up the first
\(n\) positions of its array prior to the call to
insert,
it must take up the first \(n+1\) positions after.
To accomplish this, insert first places \(V\) at
position \(n\) of the array.
Of course, \(V\) is unlikely to be in the correct position.
To move \(V\) to the right place, it is compared to its
parent's value.
If the value of \(V\) is less than or equal to the value of its
parent, then it is in the correct place and the insert routine is
finished.
If the value of \(V\) is greater than that of its parent, then
the two elements swap positions.
From here, the process of comparing \(V\) to its (current)
parent continues until \(V\) reaches its correct position.
Since the heap is a complete binary tree, its height is guaranteed to be the minimum possible. In particular, a heap containing \(n\) nodes will have a height of \(\Theta(\log n)\). Intuitively, we can see that this must be true because each level that we add will slightly more than double the number of nodes in the tree (the \(i\) th level has \(2^i\) nodes, and the sum of the first \(i\) levels is \(2^{i+1}-1\)). Starting at 1, we can double only \(\log n\) times to reach a value of \(n\). To be precise, the height of a heap with \(n\) nodes is \(\lceil \log n + 1 \rceil\).
Each call to insert takes \(\Theta(\log n)\) time in the
worst case, because the value being inserted can move at most the
distance from the bottom of the tree to the top of the tree.
Thus, to insert \(n\) values into the heap, if we insert them
one at a time, will take \(\Theta(n \log n)\) time in the
worst case.
12.17.2. Building a Heap¶
If all \(n\) values are available at the beginning of the building process, we can build the heap faster than just inserting the values into the heap one by one. Consider this example, with two possible ways to heapify an initial set of values in an array.

Figure 12.17.1: Two series of exchanges to build a max heap. (a) This heap is built by a series of nine exchanges in the order (4-2), (4-1), (2-1), (5-2), (5-4), (6-3), (6-5), (7-5), (7-6). (b) This heap is built by a series of four exchanges in the order (5-2), (7-3), (7-1), (6-1).
From this example, it is clear that the heap for any given set of numbers is not unique, and we see that some rearrangements of the input values require fewer exchanges than others to build the heap. So, how do we pick the best rearrangement?
One good algorithm stems from induction. Suppose that the left and right subtrees of the root are already heaps, and \(R\) is the name of the element at the root. This situation is illustrated by this figure:
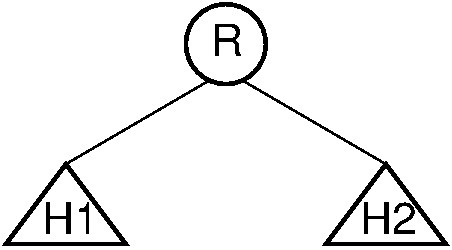
Figure 12.17.2: Final stage in the heap-building algorithm. Both subtrees of node \(R\) are heaps. All that remains is to push \(R\) down to its proper level in the heap.
In this case there are two possibilities.
- \(R\) has a value greater than or equal to its two children. In this case, construction is complete.
- \(R\) has a value less than one or both of its children.
\(R\) should be exchanged with the child that has
greater value.
The result will be a heap, except that \(R\)
might still be less than one or both of its (new) children.
In this case, we simply continue the process of "pushing down"
\(R\) until it reaches a level where it is greater than its
children, or is a leaf node.
This process is implemented by the private method
siftdown.
This approach assumes that the subtrees are already heaps, suggesting that a complete algorithm can be obtained by visiting the nodes in some order such that the children of a node are visited before the node itself. One simple way to do this is simply to work from the high index of the array to the low index. Actually, the build process need not visit the leaf nodes (they can never move down because they are already at the bottom), so the building algorithm can start in the middle of the array, with the first internal node.
Here is a visualization of the heap build process.
Method buildHeap implements the building algorithm.
What is the cost of buildHeap?
Clearly it is the sum of the costs for the calls to siftdown.
Each siftdown operation can cost at most the number of
levels it takes for the node being sifted to reach the bottom of the
tree.
In any complete tree, approximately half of the nodes are leaves
and so cannot be moved downward at all.
One quarter of the nodes are one level above the leaves, and so their
elements can move down at most one level.
At each step up the tree we get half the number of nodes as were at
the previous level, and an additional height of one.
The maximum sum of total distances that elements can go is
therefore
This summation is known to have a closed-form solution of approximately 2, so this algorithm takes \(\Theta(n)\) time in the worst case. This is far better than building the heap one element at a time, which would cost \(\Theta(n \log n)\) in the worst case. It is also faster than the \(\Theta(n \log n)\) average-case time and \(\Theta(n^2)\) worst-case time required to build the BST.
12.17.3. Removing from the heap¶
Because the heap is \(\log n\) levels deep, the cost of deleting the maximum element is \(\Theta(\log n)\) in the average and worst cases.
12.17.4. Priority Queues¶
The heap is a natural implementation for the priority queue discussed
at the beginning of this section.
Jobs can be added to the heap (using their priority value as the
ordering key) when needed.
Method removemax can be called whenever a new job is to be
executed.
Some applications of priority queues require the ability to change the
priority of an object already stored in the queue.
This might require that the object's position in the heap representation
be updated.
Unfortunately, a max heap is not efficient when searching for an
arbitrary value; it is only good for finding the maximum value.
However, if we already know the index for an object within the heap,
it is a simple matter to update its priority (including changing its
position to maintain the heap property) or remove it.
The remove method takes as input the position of the
node to be removed from the heap.
A typical implementation for priority queues requiring updating of
priorities will need to use an auxiliary data structure that supports
efficient search for objects (such as a BST).
Records in the auxiliary data structure will store
the object's heap index, so that the object can be
deleted from the heap and reinserted with its new priority.
Priority queues can be helpful for solving graph problems such as
single-source shortest paths
and
minimal-cost spanning tree.
For a story about Priority Queues and dragons, see Computational Fairy Tales: Stacks, Queues, Priority Queues, and the Prince's Complaint Line.
