

8.6. Asymptotic Analysis and Upper Bounds¶
8.6.1. Asymptotic Analysis and Upper Bounds¶
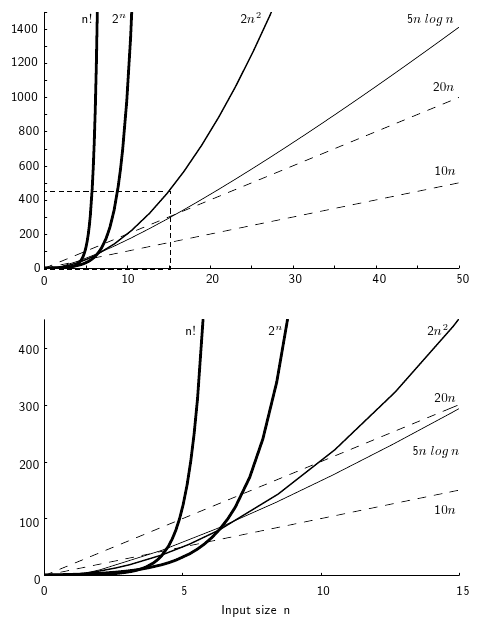
Figure 8.6.1: Two views of a graph illustrating the growth rates for six equations. The bottom view shows in detail the lower-left portion of the top view. The horizontal axis represents input size. The vertical axis can represent time, space, or any other measure of cost.
Despite the larger constant for the curve labeled \(10 n\) in the figure above, \(2 n^2\) crosses it at the relatively small value of \(n = 5\). What if we double the value of the constant in front of the linear equation? As shown in the graph, \(20 n\) is surpassed by \(2 n^2\) once \(n = 10\). The additional factor of two for the linear growth rate does not much matter. It only doubles the \(x\)-coordinate for the intersection point. In general, changes to a constant factor in either equation only shift where the two curves cross, not whether the two curves cross.
When you buy a faster computer or a faster compiler, the new problem size that can be run in a given amount of time for a given growth rate is larger by the same factor, regardless of the constant on the running-time equation. The time curves for two algorithms with different growth rates still cross, regardless of their running-time equation constants. For these reasons, we usually ignore the constants when we want an estimate of the growth rate for the running time or other resource requirements of an algorithm. This simplifies the analysis and keeps us thinking about the most important aspect: the growth rate. This is called asymptotic algorithm analysis. To be precise, asymptotic analysis refers to the study of an algorithm as the input size "gets big" or reaches a limit (in the calculus sense). However, it has proved to be so useful to ignore all constant factors that asymptotic analysis is used for most algorithm comparisons.
In rare situations, it is not reasonable to ignore the constants. When comparing algorithms meant to run on small values of \(n\), the constant can have a large effect. For example, if the problem requires you to sort many collections of exactly five records, then a sorting algorithm designed for sorting thousands of records is probably not appropriate, even if its asymptotic analysis indicates good performance. There are rare cases where the constants for two algorithms under comparison can differ by a factor of 1000 or more, making the one with lower growth rate impractical for typical problem sizes due to its large constant. Asymptotic analysis is a form of "back of the envelope" estimation for algorithm resource consumption. It provides a simplified model of the running time or other resource needs of an algorithm. This simplification usually helps you understand the behavior of your algorithms. Just be aware of the limitations to asymptotic analysis in the rare situation where the constant is important.
8.6.1.1. Upper Bounds¶
Several terms are used to describe the running-time equation for an algorithm. These terms—and their associated symbols—indicate precisely what aspect of the algorithm's behavior is being described. One is the upper bound for the growth of the algorithm's running time. It indicates the upper or highest growth rate that the algorithm can have.
Because the phrase "has an upper bound to its growth rate of \(f(n)\)" is long and often used when discussing algorithms, we adopt a special notation, called big-Oh notation. If the upper bound for an algorithm's growth rate (for, say, the worst case) is (f(n)), then we would write that this algorithm is "in the set \(O(f(n))\) in the worst case" (or just "in \(O(f(n))\) in the worst case"). For example, if \(n^2\) grows as fast as \(\mathbf{T}(n)\) (the running time of our algorithm) for the worst-case input, we would say the algorithm is "in \(O(n^2)\) in the worst case".
The following is a precise definition for an upper bound. \(\mathbf{T}(n)\) represents the true running time of the algorithm. \(f(n)\) is some expression for the upper bound.
For \(\mathbf{T}(n)\) a non-negatively valued function, \(\mathbf{T}(n)\) is in set \(O(f(n))\) if there exist two positive constants \(c\) and \(n_0\) such that \(\mathbf{T}(n) \leq cf(n)\) for all \(n > n_0\).
Constant \(n_0\) is the smallest value of \(n\) for which the claim of an upper bound holds true. Usually \(n_0\) is small, such as 1, but does not need to be. You must also be able to pick some constant \(c\), but it is irrelevant what the value for \(c\) actually is. In other words, the definition says that for all inputs of the type in question (such as the worst case for all inputs of size \(n\)) that are large enough (i.e., \(n > n_0\)), the algorithm always executes in less than or equal to \(cf(n)\) steps for some constant \(c\).
Example 8.6.1
Consider the sequential search algorithm for finding a specified value in an array of integers. If visiting and examining one value in the array requires \(c_s\) steps where \(c_s\) is a positive number, and if the value we search for has equal probability of appearing in any position in the array, then in the average case \(\mathbf{T}(n) = c_s n/2\). For all values of \(n > 1\), \(c_s n/2 \leq c_s n\). Therefore, by the definition, \(\mathbf{T}(n)\) is in \(O(n)\) for \(n_0 = 1\) and \(c = c_s\).
Example 8.6.2
For a particular algorithm, \(\mathbf{T}(n) = c_1 n^2 + c_2 n\) in the average case where \(c_1\) and \(c_2\) are positive numbers. Then,
for all \(n > 1\). So, \(\mathbf{T}(n) \leq c n^2\) for \(c = c_1 + c_2\), and \(n_0 = 1\). Therefore, \(\mathbf{T}(n)\) is in \(O(n^2)\) by the second definition.
Example 8.6.3
Assigning the value from the first position of an array to a variable takes constant time regardless of the size of the array. Thus, \(\mathbf{T}(n) = c\) (for the best, worst, and average cases). We could say in this case that \(\mathbf{T}(n)\) is in \(O(c)\). However, it is traditional to say that an algorithm whose running time has a constant upper bound is in \(O(1)\).
If someone asked you out of the blue "Who is the best?" your natural reaction should be to reply "Best at what?" In the same way, if you are asked "What is the growth rate of this algorithm", you would need to ask "When? Best case? Average case? Or worst case?" Some algorithms have the same behavior no matter which input instance of a given size that they receive. An example is finding the maximum in an array of integers. But for many algorithms, it makes a big difference which particular input of a given size is involved, such as when searching an unsorted array for a particular value. So any statement about the upper bound of an algorithm must be in the context of some specific class of inputs of size \(n\). We measure this upper bound nearly always on the best-case, average-case, or worst-case inputs. Thus, we cannot say, "this algorithm has an upper bound to its growth rate of \(n^2\)" because that is an incomplete statement. We must say something like, "this algorithm has an upper bound to its growth rate of \(n^2\) in the average case".
Knowing that something is in \(O(f(n))\) says only how bad things can be. Perhaps things are not nearly so bad. Because sequential search is in \(O(n)\) in the worst case, it is also true to say that sequential search is in \(O(n^2)\). But sequential search is practical for large \(n\) in a way that is not true for some other algorithms in \(O(n^2)\). We always seek to define the running time of an algorithm with the tightest (lowest) possible upper bound. Thus, we prefer to say that sequential search is in \(O(n)\). This also explains why the phrase "is in \(O(f(n))\)" or the notation "\(\in O(f(n))\)" is used instead of "is \(O(f(n))\)" or "\(= O(f(n))\)". There is no strict equality to the use of big-Oh notation. \(O(n)\) is in \(O(n^2)\), but \(O(n^2)\) is not in \(O(n)\).
8.6.1.2. Simplifying Rules¶
Once you determine the running-time equation for an algorithm, it really is a simple matter to derive the big-Oh expressions from the equation. You do not need to resort to the formal definitions of asymptotic analysis. Instead, you can use the following rules to determine the simplest form.
- If \(f(n)\) is in \(O(g(n))\) and \(g(n)\) is in \(O(h(n))\), then \(f(n)\) is in \(O(h(n))\).
- If \(f(n)\) is in \(O(k g(n))\) for any constant \(k > 0\), then \(f(n)\) is in \(O(g(n))\).
- If \(f_1(n)\) is in \(O(g_1(n))\) and \(f_2(n)\) is in \(O(g_2(n))\), then \(f_1(n) + f_2(n)\) is in \(O(\max(g_1(n), g_2(n)))\).
- If \(f_1(n)\) is in \(O(g_1(n))\) and \(f_2(n)\) is in \(O(g_2(n))\), then \(f_1(n) f_2(n)\) is in \(O(g_1(n) g_2(n))\).
The first rule says that if some function \(g(n)\) is an upper bound for your cost function, then any upper bound for \(g(n)\) is also an upper bound for your cost function.
The significance of rule (2) is that you can ignore any multiplicative constants in your equations when using big-Oh notation.
Rule (3) says that given two parts of a program run in sequence (whether two statements or two sections of code), you need consider only the more expensive part.
Rule (4) is used to analyze simple loops in programs. If some action is repeated some number of times, and each repetition has the same cost, then the total cost is the cost of the action multiplied by the number of times that the action takes place.
Taking the first three rules collectively, you can ignore all constants and all lower-order terms to determine the asymptotic growth rate for any cost function. The advantages and dangers of ignoring constants were discussed near the beginning of this section. Ignoring lower-order terms is reasonable when performing an asymptotic analysis. The higher-order terms soon swamp the lower-order terms in their contribution to the total cost as (n) becomes larger. Thus, if \(\mathbf{T}(n) = 3 n^4 + 5 n^2\), then \(\mathbf{T}(n)\) is in \(O(n^4)\). The \(n^2\) term contributes relatively little to the total cost for large \(n\).
From now on, we will use these simplifying rules when discussing the cost for a program or algorithm.


