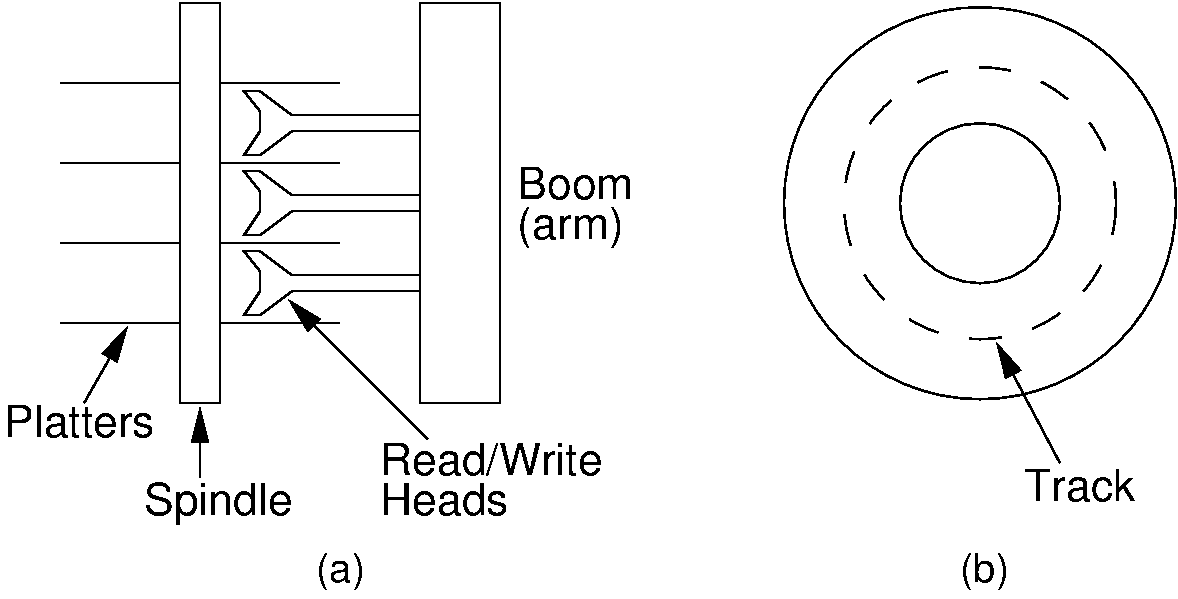
17.1.1.3. Primary vs. Secondary Storage¶
Primary storage: Main memory (RAM)
- Secondary Storage: Peripheral devices
Disk drives
Tape drives
Flash drives
Show Source | | About « 8.17. Sorting Summary Exercises :: Contents :: 9.2. Primary versus Secondary Storage »
- Logical view of files:
An a array of bytes.
A file pointer marks the current position.
- Three fundamental operations:
Read bytes from current position (move file pointer)
Write bytes to current position (move file pointer)
Set file pointer to specified byte position.
RandomAccessFile(String name, String mode)
close()
read(byte[] b)
write(byte[] b)
seek(long pos)
Primary storage: Main memory (RAM)
- Secondary Storage: Peripheral devices
Disk drives
Tape drives
Flash drives
\[\begin{split}\begin{array}{l|r|r|r|r|r|r|r} \hline \textbf{Medium}& 1996 & 1997 & 2000 & 2004 & 2006 & 2008 & 2011\\ \hline \textbf{RAM}& \$45.00 & 7.00 & 1.500 & 0.3500 & 0.1500 & 0.0339 & 0.0138\\ \textbf{Disk}& 0.25 & 0.10 & 0.010 & 0.0010 & 0.0005 & 0.0001 & 0.0001\\ \textbf{USB drive}& -- & -- & -- & 0.1000 & 0.0900 & 0.0029 & 0.0018\\ \textbf{Floppy}& 0.50 & 0.36 & 0.250 & 0.2500 & -- & -- & --\\ \textbf{Tape}& 0.03 & 0.01 & 0.001 & 0.0003 & -- & -- & --\\ \textbf{Solid State}& -- & -- & -- & -- & -- & -- & 0.0021\\ \hline \end{array}\end{split}\]
(Costs per Megabyte)
RAM is usually volatile.
RAM is about 1/2 million times faster than disk.
- Minimize the number of disk accesses!
Arrange information so that you get what you want with few disk accesses.
Arrange information to minimize future disk accesses.
An organization for data on disk is often called a file structure.
Disk-based space/time tradeoff: Compress information to save processing time by reducing disk accesses.
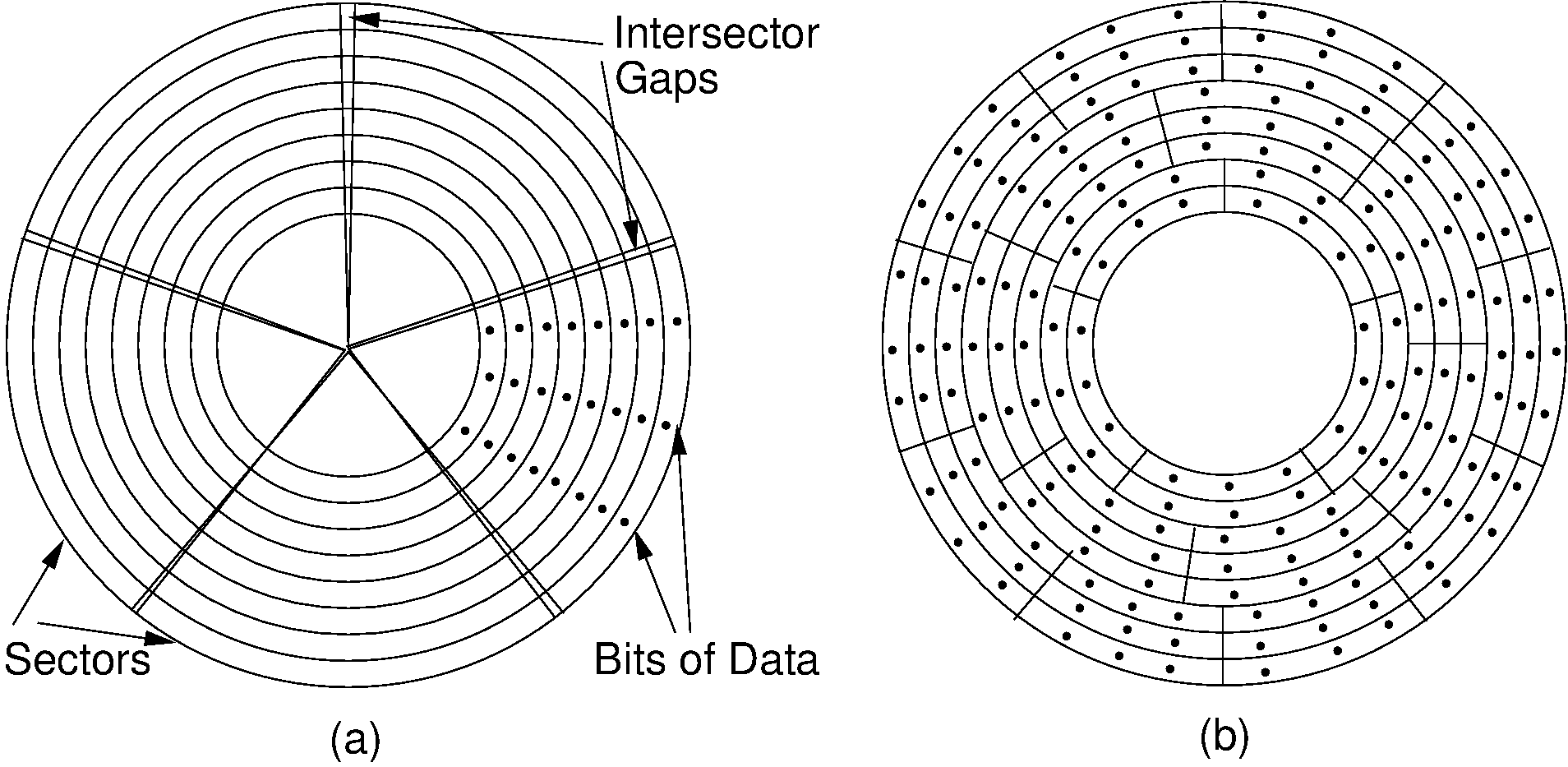
A sector is the basic unit of I/O.
Locality of Reference: When record is read from disk, next request is likely to come from near the same place on the disk.
Cluster: Smallest unit of file allocation, usually several sectors.
Extent: A group of physically contiguous clusters.
Internal fragmentation: Wasted space within sector if record size does not match sector size; wasted space within cluster if file size is not a multiple of cluster size.
Seek time: Time for I/O head to reach desired track. Largely determined by distance between I/O head and desired track.
Track-to-track time: Minimum time to move from one track to an adjacent track.
Average Access time: Average time to reach a track for random access.
- Rotational Delay or Latency: Time for data to rotate under I/O head.
One half of a rotation on average.
At 7200 rpm, this is 8.3/2 = 4.2ms.
- Transfer time: Time for data to move under the I/O head.
At 7200 rpm: Number of sectors read/Number of sectors per track * 8.3ms.
16.8 GB disk on 10 platters = 1.68GB/platter
13,085 tracks/platter
256 sectors/track
512 bytes/sector
Track-to-track seek time: 2.2 ms
Average seek time: 9.5ms
4KB clusters, 32 clusters/track.
5400RPM
Read a 1MB file divided into 2048 records of 512 bytes (1 sector) each.
Assume all records are on 8 contiguous tracks.
First track: 9.5 + (11.1)(1.5) = 26.2 ms
Remaining 7 tracks: 2.2 + (11.1)(1.5) = 18.9ms.
Total: 26.2 + 7 * 18.9 = 158.5ms
Read a 1MB file divided into 2048 records of 512 bytes (1 sector) each.
Assume all file clusters are randomly spread across the disk.
256 clusters. Cluster read time is 8/256 of a rotation for about 5.9ms for both latency and read time.
256(9.5 + 5.9) is about 3942ms or nearly 4 sec.
Read time for one track: \(9.5 + (11.1)(1.5) = 26.2\) ms
Read time for one sector: \(9.5 + 11.1/2 + (1/256)11.1 = 15.1\) ms
Read time for one byte: \(9.5 + 11.1/2 = 15.05\) ms
Nearly all disk drives read/write one sector (or more) at every I/O access
Also referred to as a page or block
Samsung Spinpoint T166
500GB (nominal)
7200 RPM
Track to track: 0.8 ms
Average track access: 8.9 ms
Bytes/sector: 512
6 surfaces/heads
The information in a sector is stored in a buffer or cache.
If the next I/O access is to the same buffer, then no need to go to disk.
Disk drives usually have one or more input buffers and one or more output buffers.
A series of buffers used by an application to cache disk data is called a buffer pool.
Virtual memory uses a buffer pool to imitate greater RAM memory by actually storing information on disk and “swapping” between disk and RAM.
Which buffer should be replaced when new data must be read?
First-in, First-out: Use the first one on the queue.
Least Frequently Used (LFU): Count buffer accesses, reuse the least used.
Least Recently used (LRU): Keep buffers on a linked list. When buffer is accessed, bring it to front. Reuse the one at end.
// ADT for buffer pools using the message-passing style public interface BufferPoolADT { // Copy "sz" bytes from "space" to position "pos" in the buffered storage public void insert(byte[] space, int sz, int pos); // Copy "sz" bytes from position "pos" of the buffered storage to "space" public void getbytes(byte[] space, int sz, int pos); }
// ADT for buffer pools using the buffer-passing style public interface BufferPoolADT { // Return pointer to the requested block public byte[] getblock(int block); // Set the dirty bit for the buffer holding "block" public void dirtyblock(int block); // Tell the size of a buffer public int blocksize(); };
- Disadvantage of message passing:
Messages are copied and passed back and forth.
- Disadvantages of buffer passing:
The user is given access to system memory (the buffer itself)
The user must explicitly tell the buffer pool when buffer contents have been modified, so that modified data can be rewritten to disk when the buffer is flushed.
The pointer might become stale when the bufferpool replaces the contents of a buffer.
Be able to avoid reading data when the block contents will be replaced.
Be able to support multiple users accessing a buffer, and independently releasing a buffer.
Don’t make an active buffer stale.
// Improved ADT for buffer pools using the buffer-passing style. // Most user functionality is in the buffer class, not the buffer pool itself. // A single buffer in the buffer pool public interface BufferADT { // Read the associated block from disk (if necessary) and return a // pointer to the data public byte[] readBlock(); // Return a pointer to the buffer's data array (without reading from disk) public byte[] getDataPointer(); // Flag buffer's contents as having changed, so that flushing the // block will write it back to disk public void markDirty(); // Release the block's access to this buffer. Further accesses to // this buffer are illegal public void releaseBuffer(); }
public interface BufferPoolADT { // Relate a block to a buffer, returning a pointer to a buffer object Buffer acquireBuffer(int block); }
- Problem: Sorting data sets too large to fit into main memory.
Assume data are stored on disk drive.
To sort, portions of the data must be brought into main memory, processed, and returned to disk.
An external sort should minimize disk accesses.
Secondary memory is divided into equal-sized blocks (512, 1024, etc…)
A basic I/O operation transfers the contents of one disk block to/from main memory.
Under certain circumstances, reading blocks of a file in sequential order is more efficient. (When?)
Primary goal is to minimize I/O operations.
Assume only one disk drive is available.
- Often, records are large, keys are small.
Ex: Payroll entries keyed on ID number
Approach 1: Read in entire records, sort them, then write them out again.
Approach 2: Read only the key values, store with each key the location on disk of its associated record.
After keys are sorted the records can be read and rewritten in sorted order.
Quicksort requires random access to the entire set of records.
- Better: Modified Mergesort algorithm.
Process \(n\) elements in \(\Theta(\log n)\) passes.
A group of sorted records is called a run.
1. Split the file into two files.2. Read in a block from each file.3. Take first record from each block, output them in sorted order.4. Take next record from each block, output them to a second file in sorted order.5. Repeat until finished, alternating between output files. Read new input blocks as needed.6. Repeat steps 2-5, except this time input files have runs of two sorted records that are merged together.7. Each pass through the files provides larger runs.
Is each pass through input and output files sequential?
What happens if all work is done on a single disk drive?
How can we reduce the number of Mergesort passes?
- In general, external sorting consists of two phases:
Break the files into initial runs
Merge the runs together into a single run.
- General approach:
Read as much of the file into memory as possible.
Perform an in-memory sort.
Output this group of records as a single run.
Break available memory into an array for the heap, an input buffer, and an output buffer.
Fill the array from disk.
Make a min-heap.
Send the smallest value (root) to the output buffer.
If the next key in the file is greater than the last value output, then
Replace the root with this key
else
Replace the root with the last key in the array
Add the next record in the file to a new heap (actually, stick it at the end of the array).
Imagine a snowplow moving around a circular track on which snow falls at a steady rate.
At any instant, there is a certain amount of snow S on the track. Some falling snow comes in front of the plow, some behind.
During the next revolution of the plow, all of this is removed, plus 1/2 of what falls during that revolution.
Thus, the plow removes 2S amount of snow.
- Simple Mergesort: Place runs into two files.
Merge the first two runs to output file, then next two runs, etc.
- Repeat process until only one run remains.
How many passes for r initial runs?
Is there benefit from sequential reading?
Is working memory well used?
Need a way to reduce the number of passes.
With replacement selection, each initial run is several blocks long.
Assume each run is placed in separate file.
Read the first block from each file into memory and perform an r-way merge.
When a buffer becomes empty, read a block from the appropriate run file.
Each record is read only once from disk during the merge process.
Assume working memory is \(b\) blocks in size.
How many runs can be processed at one time?
The runs are \(2b\) blocks long (on average).
How big a file can be merged in one pass?
Larger files will need more passes – but the run size grows quickly!
This approach trades (\(\log b\)) (possibly) sequential passes for a single or very few random (block) access passes.
- A good external sorting algorithm will seek to do the following:
Make the initial runs as long as possible.
At all stages, overlap input, processing and output as much as possible.
Use as much working memory as possible. Applying more memory usually speeds processing.
If possible, use additional disk drives for more overlapping of processing with I/O, and allow for more sequential file processing.
Contact Us || Privacy | | License « 8.17. Sorting Summary Exercises :: Contents :: 9.2. Primary versus Secondary Storage »